scikit-learn Pipelines meet Knowledge Graphs
The Python kgextension Package
Abstract
Python is currently the most used platform for data science and machine learning. At the same time, public knowledge graphs have been identified as a valuable source of background knowledge in many data science tasks. In this paper, we introduce the kgextension package for Python, which allows for using knowledge graph in data science pipelines built in Python. The demo shows how data from public knowledge graphs such as DBpedia and Wikidata can be used in data mining pipelines based on the popular Python package scikit-learn. We demonstrate the package's utility by showing that the prediction accuracy on a popular Kaggle task can be significantly increased by using background knoweldge from DBpedia.
Package Functionalities
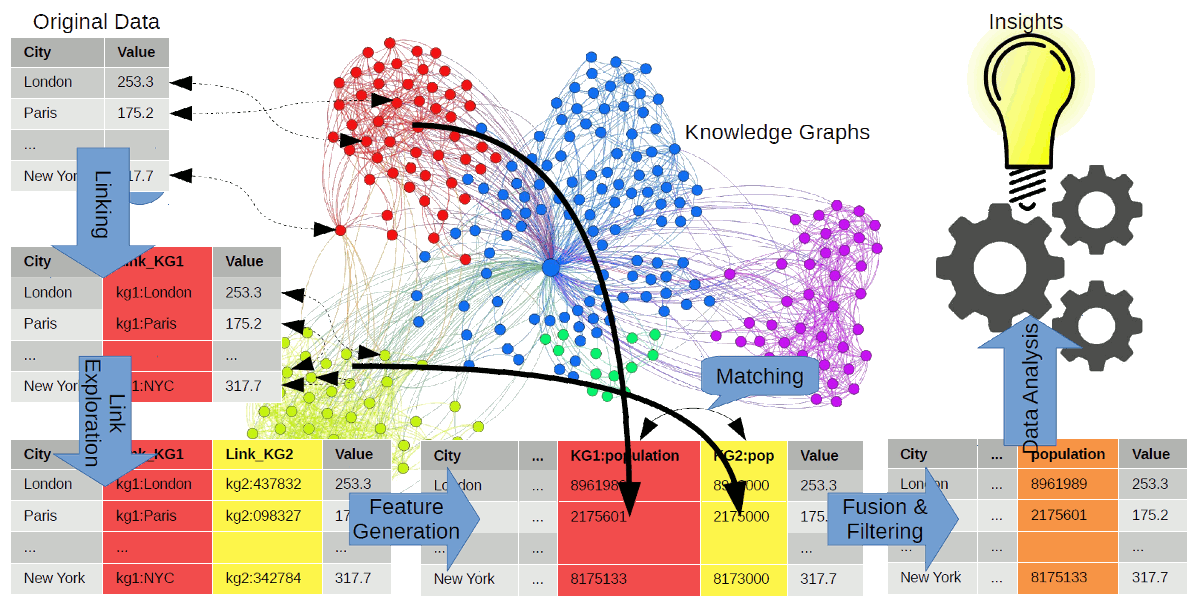
- Linking and Link Exploration
- Feature Generation
- Feature Filtering
- Matching and Fusion
Demonstration Contents
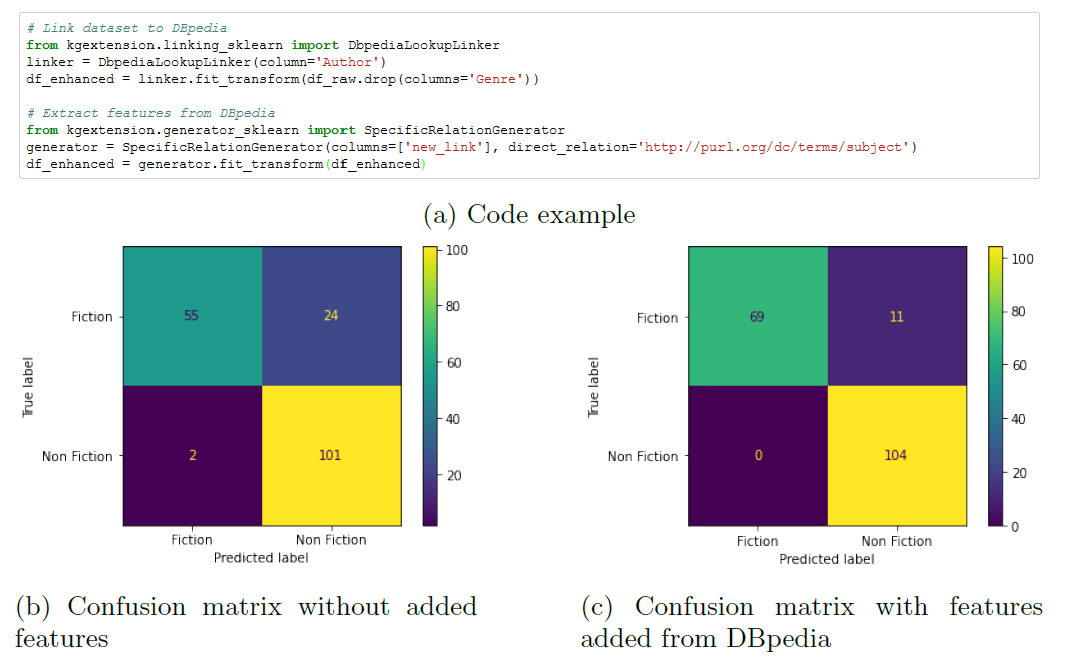
- prediction task from Kaggle: Amazon Top 50 Bestselling Books 2009 - 2019 to classify books in fiction and non-fiction
- extend the dataset with information from different public knowledge graphs
- accuracy increases significantly from 0.86 to 0.94
Future Developments
- integrate novel methods for linking and libraries for creating knowledge graph embedding vectors
- extend the dataset with information from different public knowledge graphs
- integrate efficient generators for Triple Pattern Fragment endpoints and HDT files
Link to the demo
Link to Github Repository kgextension and Read the Docs