
In the following we present the results of the OAEI 2011.5 evaluation of the anatomy track. If you notice any kind of error (wrong numbers, incorrect information on a matching system) do not hesitate to contact Christian Meilicke (mail see below).
In the context of OAEI 2011.5 we focus in our evaluation on three aspects:
We have not included what has been known as subtask #2 and #3 in the previous years (modifying the configuration of a system to favor precision over recall or vice versa). Moreover, we have omitted the analysis of subtask #4. This task is about exploiting an additional input alignment. In case you are one of the participants and you are interested in the evaluation of this functionality, feel free to contact us! We might be able to put some additional effort in this subject.
You can download the complete set of all generated alignments. These alignments have been generated by executing the tools with the help of the SEALS infrastructure. All results presented in the following are based on analyzing these alignments.
The main results of our evaluation are depicted in the following table. We evaluated all systems that submitted an executable version to OAEI 2011 or 2011.5. Thus, we had three types of systems (see second column of the table).
We can see that none of the systems can top the results of AgreementMaker submitted for OAEI 2011. However, GOMMA generates an alignment with nearly the same F-measure. We have executed the GOMMA system in two settings. In one setting we activated the usage of background knowledge (bk) and in another setting we deactivated this feature (no-bk).
| Matching system | Status/Version | Size | Precision | Recall | Recall+ | F-measure |
| AgrMaker | 2011 version | 1436 | 0.942 | 0.892 | 0.728 | 0.917 |
| GOMMA-bk | New | 1468 | 0.927 | 0.898 | 0.736 | 0.912 |
| CODI | Modified | 1305 | 0.96 | 0.827 | 0.562 | 0.888 |
| LogMap | Modified | 1391 | 0.918 | 0.842 | 0.588 | 0.879 |
| GOMMA-nobk | New | 1270 | 0.952 | 0.797 | 0.471 | 0.868 |
| MapSSS | Modified | 1213 | 0.934 | 0.747 | 0.337 | 0.83 |
| LogMapLt | New | 1155 | 0.956 | 0.728 | 0.29 | 0.827 |
| Lily | 2011 version | 1370 | 0.811 | 0.733 | 0.51 | 0.77 |
| StringEquiv | - | 934 | 0.997 | 0.622 | 0.000 | 0.766 |
| Aroma | 2011 version | 1279 | 0.751 | 0.633 | 0.344 | 0.687 |
| CSA | 2011 version | 2472 | 0.464 | 0.757 | 0.595 | 0.576 |
| MaasMtch | Modified | 2738 | 0.43 | 0.777 | 0.435 | 0.554 |
With respect to F-measure not much has changed for the systems CODI and LogMap. MapSSS could not generate any results for OAEI 2011; the problems of the system have been fixed in the new version. MaasMatch seems to run now with modified setting generating much more correspondences than for OAEI 2011.
Again, we observe that more systems can generate results that top the String-Equivalence baseline. Moreover, many systems are now capable of generating good results for the dataset of this track. However, there are still a few systems (AUTOMsv2, Hertuda, WeSeE, YAM++ not shown in the table) that have problems. These systems failed with an exeption, did not finish within the given time frame, or generated an empty/useless alignment (less than 1% F-measure). Note that we stopped the execution of each system after 10 hours.
We have executed all systems on virtual machines with one, two, and four cores each with 8GB RAM. The runtime results, shown as blue bars in the following figure, are based on the execution of the machines with one core. We executed each system three times reporting on the average runtimes. Note that the figure uses a logarithmic scale to depict the runtime in seconds. We have already reported in previous OAEI campaign a high variance in runtimes. This is again the case. However, there are now several systems that are able to match the ontologies in less than one minute. This is LogMap (and LogMapLite), GOMMA (with and without the use of background knowledge) and AROMA. Again, we observe that the top systems can generate a high quality alignment in a short amount of time. In general, there is no positive correlation between the quality of the alignment and a long runtime.
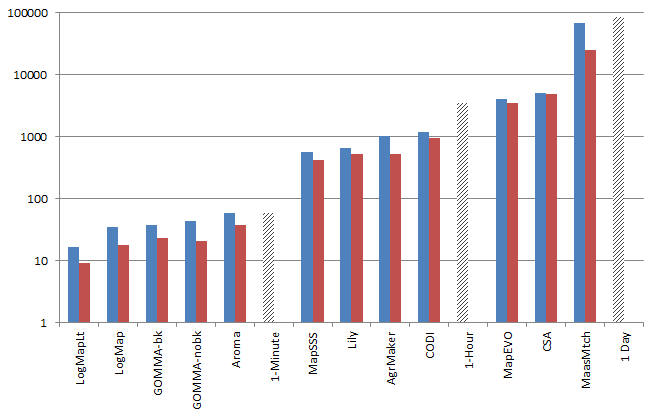
As explained above, we have also measured runtimes for running the matching systems in a 2-core and 4-core environment. However, these results are ambiguous. In particular, we observed a relatively high variance in measured runtimes. It is not always clear whether this is related to a non-deterministic component of the matching systems, or whether this might be related to uncontrolled interference in the infrastructure.
For that reason, we have supressed a detailed presentation of the results. Instead of that we decided to show the fastest run (best of three runs) in the 4-core environment for each matching system as red bar. The figure illustrates that running a system with 1-core vs. running it with 4-cores has no effect the order of systems. The differences in runtimes are too strong.
There are some systems that scale well and some systems that can exploit a multicore environment only to a very limited degree. AROMA, LogMap, GOMMA reduce their runtime on a 4-core environment up to 50-65% compared to executing the system with 1-core. The top system in terms of scalability with respect to number of available cores is MaasMatch. Here we measured a reduction to ~40%. Note that a "perfect" system - in terms of scalability - would reduce its runtime to 25% in this setting.
In the future we have to execute more runs (>10) for each system to reduce random influences on our measurements. Moreover, we have to put our attention also to scalability issues related to the availability of memory.
This track is organized by Christian Meilicke and Heiner Stuckenschmidt. If you have any problems working with the ontologies, any questions or suggestions, feel free to write an email to christian [at] informatik [.] uni-mannheim [.] de