This page links to the resources (dataset and executable code) that have been used to produce the results presented in [1]. The following content is available:
Last update: 12th October 2018, added author version of the paper. Previous update: 14th June 2018, added WN18RR annotated test set and code for applying the rules learned by AMIE (which was missing before).
An authors version of the paper is available here.
We used the datasets FB15k, FB15k-237, WN18 and WN18RR that are available via the specified links.
We generated and used the following annotated test sets for the fine-grained analysis reported in Section 4.2 and 4.3.
Each line refers to one completion task and contains tab-separated the following entries.
Download RuleN here and use it as explained in the following. The (not so nicely documented) source code of RuleN is available on request by mail (contact see below). RuleN needs to be executed in two steps. First the rules are learned from the training set and stored. We used RuleN in a setting like P12[3],C with different sample sizes for P12 and P3. This cannot be configured like this explicitly (which is just a minor limitation of the current implementation). Only the maximum path length can be set. So we have run it once in the P12,C setting with higher sample size and in the P123 setting with lower sample size. The resulting rule files need to be aggregated afterwards (taking all rules from the first run and only the P3 rules from the second run). We show here only the example for the P12,C setting on WN18, its easy to change the parameters for the FB15k settings (-s1 and -s2 are both the sample size (k in the paper), -c activates the learning of constant rules).
E:\projects\RuleN>java -cp RuleN.jar de.unima.ki.arch.LearnRules -t wordnet-mlj12-train.txt -s1 1000 -s2 1000 -p 2 -c -o learned_rules.txt
* read 141442 triples
* set up index for 18 relations, 40504 head entities, and 40551 tail entities
* learning rules
* _verb_group (1138 facts)
* P1=7 P2=68 C=1748 => 1837 remain [processed ~ 5,556%]
* _hypernym (34796 facts)
...
...
finished, generated and stored 12690 tail rules and 12562 head rules in learned_rules.txt
For historical reasons, the C rules are annotated as Ca rules in the output. A serialization like P++ r1 <- r2 r3 means r1(x,z) <- r2(x,y) & r3(y,z), while a serialization like P+- r1 <- r2 r3 means r1(x,z) <- r2(x,y) & r3(z,y).
Then the rules are loaded and applied to solve the completion tasks. In our experiments we (mostly) stored the filtered top-50 candidates for each completion task.
E:\projects\RuleN>java -cp RuleN.jar de.unima.ki.arch.ApplyRules -tr wordnet-mlj12-train.txt -v wordnet-mlj12-valid.txt -t wordnet-mlj12-test.txt
-r learned_rules.txt -o predictions.txt -k 50
* read 5000 triples
* set up index for 18 relations, 4349 head entities, and 4263 tail entities
* read 5000 triples
* set up index for 18 relations, 4262 head entities, and 4338 tail entities
* read 141442 triples
* set up index for 18 relations, 40504 head entities, and 40551 tail entities
* applying rules
* set up index structure covering rules for 18=T|18=H different relations
* constructed filter set with 151442 triples
* (#0) trying to guess the tail/head of 06845599 _member_of_domain_usage 03754979
HCache=100 TCache=98
* (#100) trying to guess the tail/head of 00802946 _derivationally_related_form 01141841
HCache=198 TCache=198
* (#200) trying to guess the tail/head of 00940384 _hyponym 00903212
HCache=295 TCache=295
...
...
* done with rule application
The generated file contains the filtered top 50 (parameter -k 50) ranking. The filtering is the reason why the validations data (-v) and the test data (-t) needs to be specified in addition to the training data (-tr) and the previously learned rules (-r). These results can then be compared against the fine grained gold standards to compute for example hits@10.
We used the AMIE version available here as AMIE+* (bottom of page).
We used slightly different threshold for learning path rules vs. constant rules, resulting in the following two command line calls of AMIE. We aggregated the results into one file. Note that rule files of AMIE contain several lines of a header section and at the end some lines that specify the runtime. These lines need to be removed when joining rule files such that the file only contains lines that represent rules.
java -XX:-UseGCOverheadLimit -Xmx4g -jar amie_plus.jar -maxad 4 -minhc 0.0 -mins 0 -minis 0 wordnet-mlj12-train.txt > p1_p2_p3.txt
java -XX:-UseGCOverheadLimit -Xmx4g -jar amie_plus.jar -fconst -mins 0 -minis 0 wordnet-mlj12-train.txt > c1_c2.txt
The same holds for FB15k and FB15k-237, with a more efficient parameter setting.
java -XX:-UseGCOverheadLimit -Xmx4g -jar amie_plus.jar -minhc 0.0 -mins 0 -minis 0 freebase_mtr100_mte100-train.txt > p1_p2.txt
java -XX:-UseGCOverheadLimit -Xmx4g -jar amie_plus.jar -fconst -maxad 2 -mins 0 -minis 0 freebase_mtr100_mte100-train.txt > c1.txt
We apply the learned rules to create a ranking. Since AMIE supports different rules that are serialized in another format than the RuleN rules, different code needs to be used to apply them. It is available here and uses the standard confidence of the mined rules (not AMIE's special PCA confidence) to make predictions.
The following command line code shows how to create the ranking predictions for WN18.
java -jar ApplyAMIERules.jar p3_c2.txt wordnet-mlj12-train.txt wordnet-mlj12-test.txt wordnet-mlj12-valid.txt pred_test.txt
The parameters are the path to rule file, training, test, and validation datasets and the path to the file where the rankings are to be stored. The top 50 rankings are generated (just rankings, without confidences).
For running RESCAL, TransE, or HolE, we have to refer to the descriptions available in the papers we cited.
We still have to present the best parameters found during hyperparameter search here.
We detected the existence of the WN18RR dataset too late to add the results for this dataset in the paper. Here we present some interesting results related to this dataset, which has been described in [2]. First we analyzed the partition to problem classes in the same way as we did for the other three datasets.
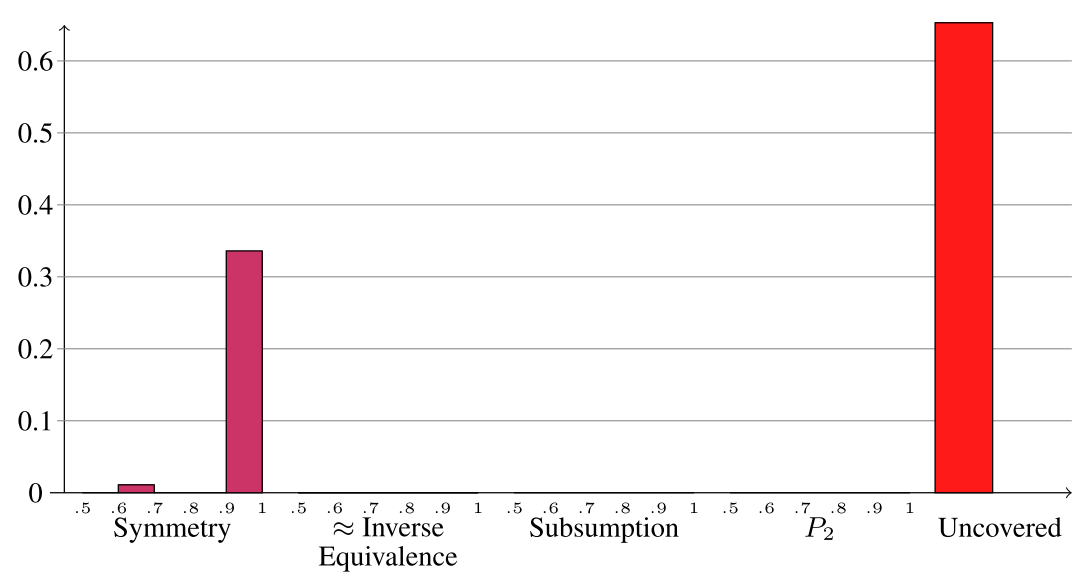
As we can see in the figure, the mostly trivial equivalence testcases have been supressed. However, even though the authors were motivated by the procedure that was applied to go from FB15 to FB15-237, the symmetry testcases have not been supressed. Overall, it seems that the dataset is modified in a more cautios way, which might also avoid the problems we mentioned w.r.t FB15-237. We have used this partitioning to compute the hits@1 and hits@10 on a finegrained level, which are presented in the following table.
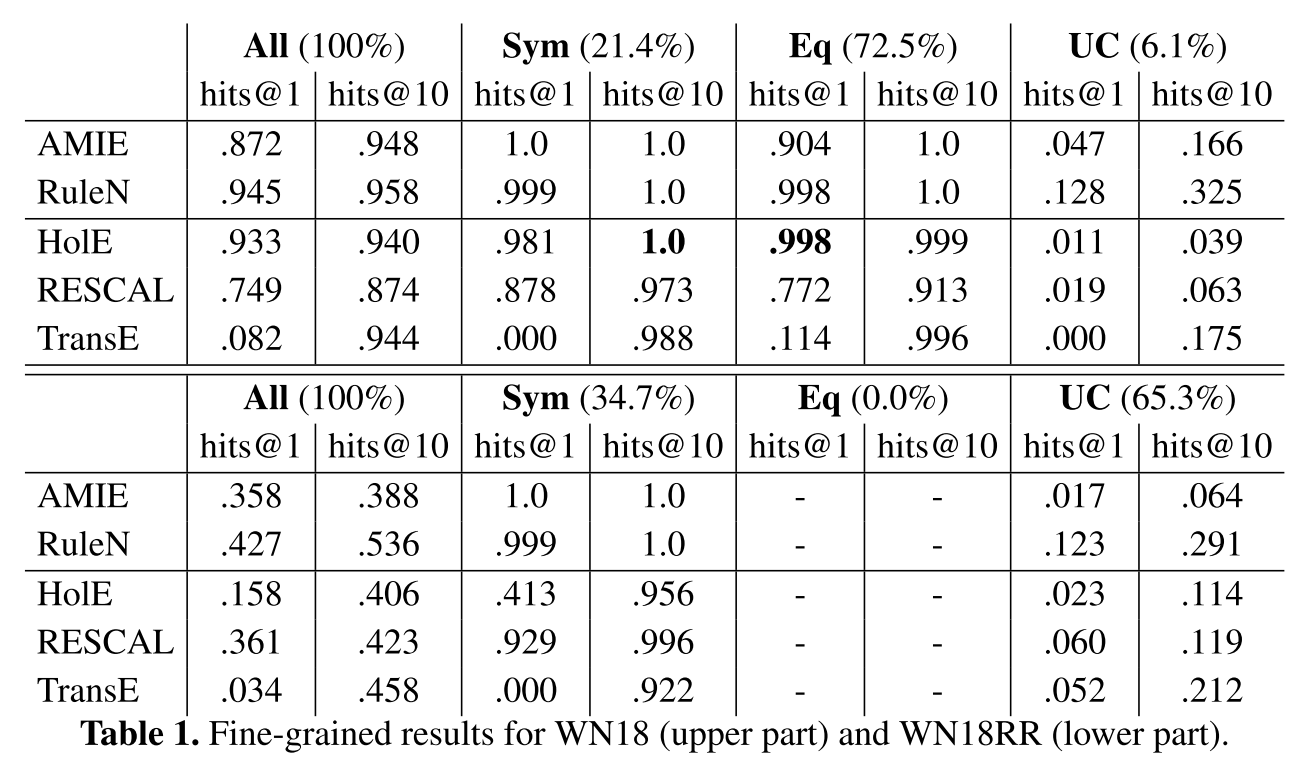
The results for the symmetry testcases are exactly as we expect them from the results we obtained on the other datasets. Bothe AMIE and RuleN clearly outperform the other methods. Morever, RuleN performs also significantly better than the other systems on the testcases annotated as Uncovered. We investigated this closer and found out that the majority of the correct hits is generated by path rules of length 3.
Note also that the top results reported in [2] for Wn18RR, where the dataset has been proposed, are 0.48, 0.49 and 0.51 in terms of hits@10, where RuleN has a score of 0.536.
In the context of analysing the WN18RR results, we realized that we missed to explain how RuleN works with cycles in body instantiations. Whenever a subpath in a path rule results in a cycle this is not counted as a valid instantiation when computing the confidence of the rule. The following rule is an example, where this makes a difference:
wife(x1,x2) & husband(b,c) & father(c,d) => father(a,d)
Without the cycle constraint this rule would have a confidence of 1.0.
If you have any questions or encounter problems in running the code, please contact christian@informatik.uni-mannheim.de.
[1] Christian Meilicke, Manuel Fink, Yanjie Wang, Daniel Ruffinelli, Rainer Gemulla, Heiner Stuckenschmidt: Fine-grained Evaluation of Rule- and Embedding-based Systems for Knowledge Graph Completion. Submitted to the ISWC 2018. Link to the paper
[2] Dettmers, T., Minervini, P., Stenetorp, P., Riedel, S.: Convolutional 2d knowledge graph embeddings. CoRR abs/1707.01476 (2017), http://arxiv.org/abs/1707.01476