This page informs about the results for the Process Model Matching track, which is a new OAEI track in 2016.
Only few systems have been marked as capable of generating alignments for the Process Model Matching track. We have tried to execute all these systems, however, some of them generated only trivial TBox mappings instead of mappings between activities. After contacting the developer of the systems, we received the feedback that the systems have been marked mistakenly and are designed for terminological matching only. We have excluded them from the evaluation. Moreover, we tried to run all systems that were marked as instance matching tools, which have been submitted as executable SEALS bundles. One of these tools (LogMap), generated meaningful results and was also added to the set of systems that we evaluated. Finally we evaluated three systems (AML, LogMap, and DKP). One of these systems was configured in two different settings related to the treatment of events-to-activity mappings. This was the tool DKP. Thus we distinguish between DKP and DKP*.
We have collected all generated alignments and we make them available in a zip-file via the following link. These alignments are the raw results that the following report is based on.
In our evaluation, we computed the well known metric precision and recall, as well as the harmonic mean known as F-measure. The dataset we used consists of several test cases. We aggregated the results and present in the following the micro average results. The gold standard we used for our evaluation is based on the gold standard that has also been used for the first evaluation experiment reported at the Process Model Matching Contest in 2015 [1]. We modified only some minor mistakes. In order to compare the results to the results obtained by the process model matching community, we present also the recomputed values of the submissions to the 2015 contest.
We extend our evaluation (“Standard” in the table below) by a new evaluation measure that makes use of a probabilistic reference alignment (“Probabilistic” in the table below). This probabilistic measure is based on a gold standard which is manually and independently generated by several domain experts. The number of votes of the annotators are applied as support values in the probabilistic evaluation. For a detailed discussion, please refer to [2].
The following table shows the results of our evaluation. Participants of the Process Model Matching Contest are depicted in grey font, while OAEI participants are shown in black font. The OAEI participants are ranked on position 1, 8/9 and 11 with an overall number of 16 systems listed in the table. Note that AML-PM at the PMMC 2015 was a matching system that was based on a predecessor of AML participating at the OAEI 2016. The good results of AML are surprising, since we expected that matching systems specifically developed for the purpose of process model matching would outperform ontology matching systems applied to the special case of process model matching. While AML contains also components that are specifically designed for the process matching task (a flooding-like structural matching algorithm), its relevant main components are components developed for ontology matching and the sub-problem of instance matching.
In the probabilistic evaluation, however, the OAEI participants (AML, LogMap, DKP, DKP*) gain position 2, 3, 9 and 10, respectively. LogMap rises from position 11 to 3. The (probabilistic) precision improves over-proportionally for this matcher, because LogMap generates many correspondences which are not included in the binary gold standard but are included in the probabilistic one. The ranking of LogMap demonstrates that a strength of the probabilistic metric lies in the broadened definition of the gold standard where weak mappings are included but softened (via the support values).
| Participants | Standard | Probabilistic | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Name | OAEI/PMMC | Size | P | R | FM | Ranking | ProP | ProR | ProFM | Ranking |
| AML | OAEI-16 | 221 | 0.719 | 0.685 | 0.702 | 1 | 0.742 | 0.283 | 0.410 | 2 |
| AML-PM | PMMC-15 | 579 | 0.269 | 0.672 | 0.385 | 14 | 0.377 | 0.398 | 0.387 | 4 |
| BPLangMatch | PMMC-15 | 277 | 0.368 | 0.440 | 0.401 | 12 | 0.532 | 0.272 | 0.360 | 8 |
| DKP | OAEI-16 | 177 | 0.621 | 0.474 | 0.538 | 8 | 0.686 | 0.219 | 0.333 | 9 |
| DKP* | OAEI-16 | 150 | 0.680 | 0.440 | 0.534 | 9 | 0.772 | 0.211 | 0.331 | 10 |
| KnoMa-Proc | PMMC-15 | 326 | 0.337 | 0.474 | 0.394 | 13 | 0.506 | 0.302 | 0.378 | 5 |
| Know-Match-SSS | PMMC-15 | 261 | 0.513 | 0.578 | 0.544 | 6 | 0.563 | 0.274 | 0.368 | 7 |
| LogMap | OAEI-16 | 267 | 0.449 | 0.517 | 0.481 | 11 | 0.594 | 0.291 | 0.390 | 3 |
| Match-SSS | PMMC-15 | 140 | 0.807 | 0.487 | 0.608 | 4 | 0.761 | 0.192 | 0.307 | 12 |
| OPBOT | PMMC-15 | 234 | 0.603 | 0.608 | 0.605 | 5 | 0.648 | 0.258 | 0.369 | 6 |
| pPalm-DS | PMMC-15 | 828 | 0.162 | 0.578 | 0.253 | 16 | 0.210 | 0.335 | 0.258 | 16 |
| RMM-NHCM | PMMC-15 | 220 | 0.691 | 0.655 | 0.673 | 2 | 0.783 | 0.297 | 0.431 | 1 |
| RMM-NLM | PMMC-15 | 164 | 0.768 | 0.543 | 0.636 | 3 | 0.681 | 0.197 | 0.306 | 13 |
| RMM-SMSL | PMMC-15 | 262 | 0.511 | 0.578 | 0.543 | 7 | 0.516 | 0.242 | 0.329 | 11 |
| RMM-VM2 | PMMC-15 | 505 | 0.216 | 0.470 | 0.296 | 15 | 0.309 | 0.294 | 0.301 | 14 |
| TripleS | PMMC-15 | 230 | 0.487 | 0.483 | 0.485 | 10 | 0.486 | 0.210 | 0.293 | 15 |
The graphics below show the probabilistic precision (ProP), probabilistic recall (ProR) and probabilistic F-Measure (ProFM) with rising threshold τ on the reference alignment (0,000; 0,375; 0,500; 0,750). The matcher LogMap mainly identifies correspondences with high support (of which many are not included in the binary gold standard). This can be observed by the minor change in the ProP and the significant increase in the ProR with higher τ. For the matcher AML, the opposite effect can be observed. The precision decreases dramatically with rising τ (accompanied by a weak increase of the ProR). This indicates that the matcher computes a high fraction of correspondences with low support value (which are partly included in the binary gold standard). For the matchers DKP and DKP*, with increasing τ, a minor decrease in ProP and increase in ProR can be observed. The ProP decreases, since the number of correspondences in the non-binary gold standard decreases (with rising τ). At the same time, the ProR increases with a lower number of correspondences (with rising τ). For details about the probabilistic metric, please refer to [2].
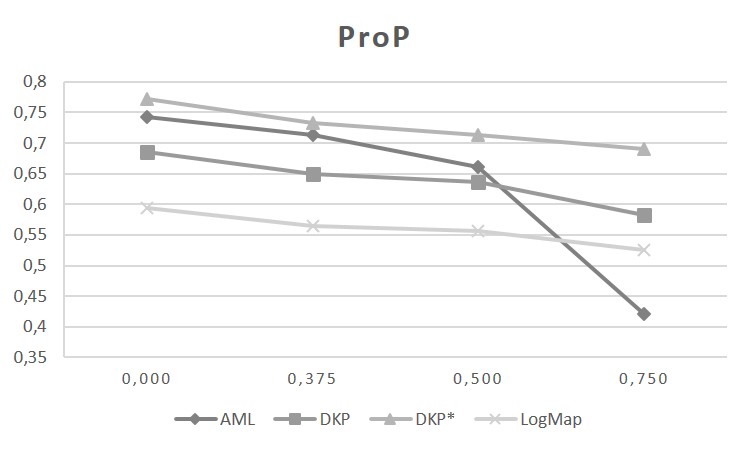
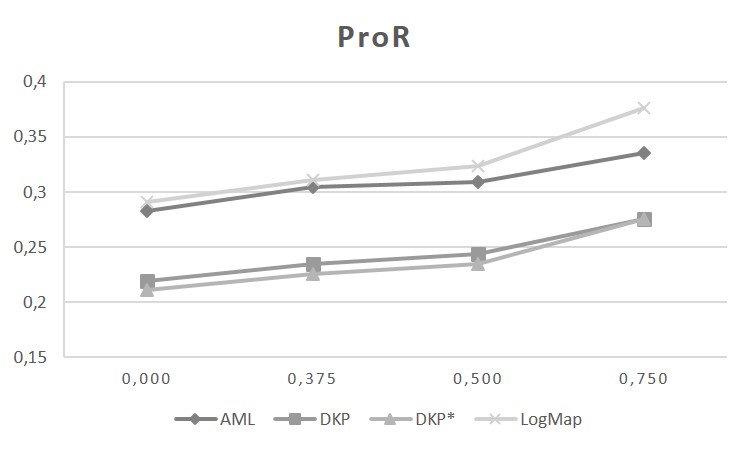
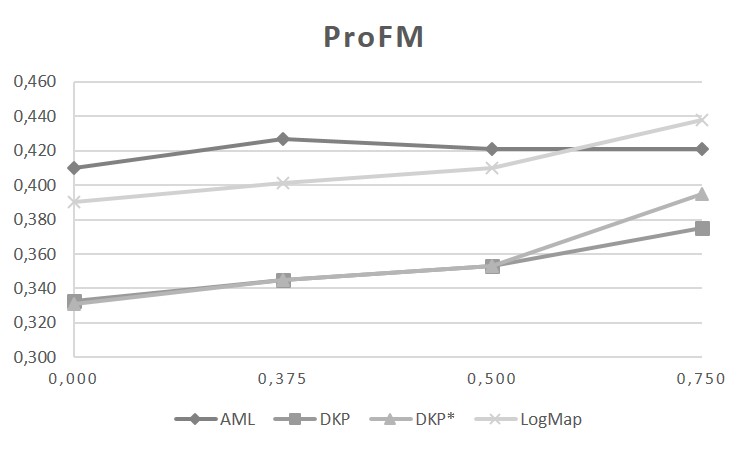
While the system DKP generates mediocre results, this indicates that the progress made in ontology matching has also a positive impact on other related matching problems, like it is the case for process model matching. While it might require to reconfigure, adapt, and extend some parts of the ontology matching systems, such a system seems to offer a good starting point which can be turned with a reasonable amount of work into a good process matching tool.
We have to emphasize that our observations are so far based on only one dataset. Moreover, only three participants decided to apply their systems to the new track of process model matching. Thus, we have to be cautious to generalize the results we observed so far. In the future we might be able to attract more participants integrating more datasets in the evaluation.
If you have any questions or remarks, feel free to contact us.
[1] Goncalo Antunes, Marzieh Bakhshandeh, Jose Borbinha, Joao Cardoso, Sharam Dadashnia, Chiara Di Francescomarino, Mauro Dragoni, Peter Fettke, Avigdor Gal, Chiara Ghidini, Philip Hake, Abderrahmane Khiat, Christopher Klinkmüller, Elena Kuss, Henrik Leopold, Peter Loos, Christian Meilicke, Tim Niesen, Catia Pesquita, Timo Péus, Andreas Schoknecht, Eitam Sheetrit, Andreas Sonntag, Heiner Stuckenschmidt, Tom Thaler, Ingo Weber, Matthias Weidlich: The Process Model Matching Contest 2015. In: 6th International Workshop on Enterprise Modelling and Information Systems Architectures (EMISA 2015), September 3-4, 2015, Innsbruck, Austria.
[2] Elena Kuss, Henrik Leopold, Han van der Aa, Heiner Stuckenschmidt, Hajo A. Reijers: Probabilistic Evaluation of Process Model Matching Techniques. ER2016, Nov. 14-17, 2016, Gifu, Japan.