About
In recent years, research in Natural Language Processing (NLP) has led to major breakthroughs in language understanding. Computational semantics is one of the key areas in NLP, and accordingly a plethora of work focused on the representations of machine-readable knowledge along orthogonal dimensions such as manual vs. automatic acquisition, lexical vs. conceptual as well as dense vs. sparse representations.
JOIN-T (Joining graph- and vector-based sense representations for semantic end-user information access) project is a collaboration between the researchers from the Data and Web Science Group at the University of Mannheim and the Language Technology Group at the University of Hamburg. JOIN-T is funded by the Deutsche Forschungsgemeinschaft (DFG).
Project overview
Disambiguated Distributional Semantic-based Sense Inventories are hybrid knowledge bases that combines the contextual information of distributional models with the conciseness and precision of manually constructed lexical networks. In contrast to dense vector representations, our resource is human readable and interpretable, and can be easily embedded within the Semantic Web ecosystem. Manual evaluation based on human judgments indicates the high quality of the resource, as well as the benefits of enriching top-down lexical knowledge resources with bottom-up distributional information from text.
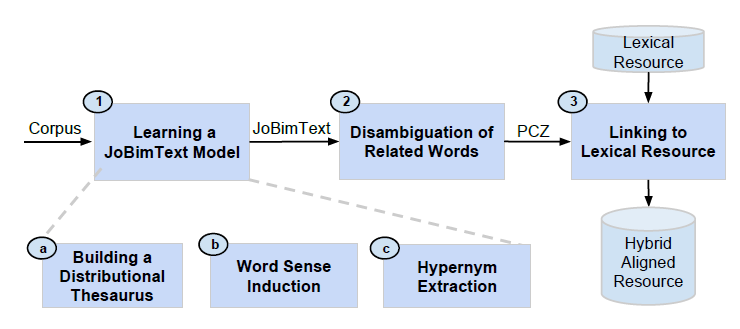
Our approach consists of three main phases:
- Learning a JoBimText model: initially, we automatically create a sense inventory from a large text collection using the pipeline of the JoBimText project.
- Disambiguation of related words: we fully disambiguate all lexical information associated with a proto-concept, i.e., similar terms and hypernyms, based on the partial disambiguation from the previous step. The result is a proto-conceptualization (PCZ). In contrast to a term-based distributional thesaurus (DT), a PCZ consists of sense-disambiguated entries, i.e., all terms have a sense identifier.
- Linking to a lexical resource: we align the PCZ with an existing lexical resource (LR). That is, we create a mapping between the two sense inventories and then combine them into a new extended sense inventory, our hybrid aligned resource. Finally, to obtain a truly unified resource, we link the “orphan” PCZ senses for which no corresponding sense could be found by inferring their type in the LR.
