Multilingual IsA (MISA) is a collection of hypernymy relations in five languages (i.e., English, Spanish, French, Italian and Dutch)
extracted from the corresponding full Wikipedia corpus.
The extraction, for each language, is based on an established set of existing (viz. found in literature) or newly defined lexico-syntactic patterns.
Similarly to WebIsADb, the resulting resource contains hypernymy relations represented as "tuples",
as well as additional information such as provenance, context of the extraction etc.
|
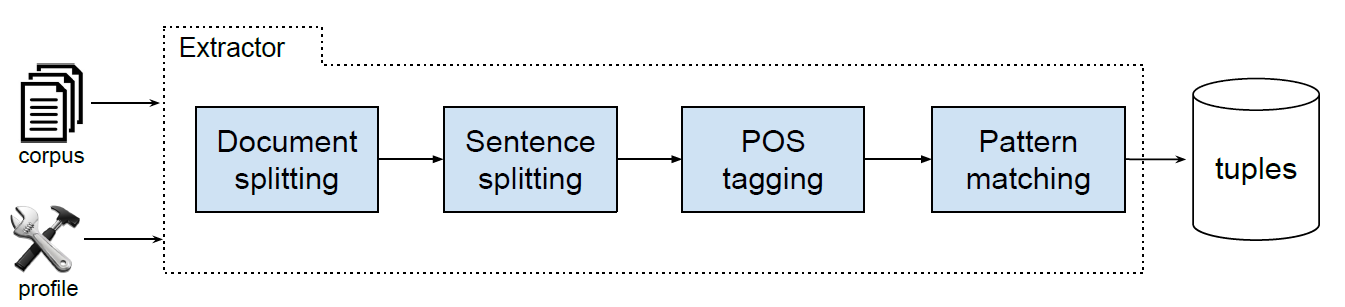
Our pipeline input includes:
- a corpus in the form of a collection of flat text (UTF-8) documents written in a specific language of interest;
- a language profile including the following language-specific information:
- patterns: the definition of lexical-syntactic patterns;
- abbreviations: a list of abbreviations (e.g., the English abbreviation "Prof." for "Professor");
- pronouns: lists of demonstratives, personals, possessives and interrogative pronouns;
- conjunctions: to identify sequences of concepts (e.g., the English "or", "and").
where abbreviations, pronouns and conjunctions are devoted to language specific noun phrase (NP) identification.
The extraction process is then divided into four main steps:
- Document splitting: in this initial phase the corpus is structured as a collection of indexed document; and titles are collected to later identify all the extraction's provenances;
- Sentence splitting: since our context of the extraction is a single sentence we split each document in separated one-line sentences;
- POS tagging: each sentence is processed with a POS tagger (we use Stanford POS-tagger for EN, FR, DE and ES corpora and TreeTagger for IT and NL corpora) to allow identification of NPs in the next step;
- Pattern matching: in this final step we find all matches between the lexico-syntactic patterns and the POS-tagged input sentence.
The output of our pipeline consists of a collection of tuples representing each pattern match, including:
- the pattern matching;
- a pair of concept sequences (T, C) where T is the sequence of definiendum NPs and C is the sequence of hypernymy NPs;
- the provenance (i.e. the corpus and document identifier identifier);
- the contextual matching sentence;
- the POS-tag sequence for the sentence.
|
 This work is partially funded by DFG, project JOIN-T
This work is partially funded by DFG, project JOIN-T