DS4DM
Data Search For Data Mining
DS4DM
Search and Integrate Tabular Data
Data Search For Data Mining
Search and Integrate Tabular Data
The BMBF-funded research project Data Search for Data Mining (DS4DM) extends the data mining plattform RapidMiner with data search and data integration functionalities which enable analysts to find relevant data in large corpora of tabular data, and to semi-automatically integrate discovered data with existing local data. Specifically, the data search functionalities allow users to extend an existing local data table with additional attributes (=columns) of their choice. E.g. if you have a table with data about companies loaded into RapidMiner, you can ask the DS4DM RapidMiner Data Search Operator to extend your table with the additional column 'Headquarter location'. The operator will search the corpus of tabular data, that is loaded into the DS4DM backend, for relevant data, will add a new 'Headquarter location' column to the user's table, and will populate the column with values from the data corpus.
The University of Mannheim team within the DS4DM project is developing the backend for the DS4DM RapidMiner Data Search Extension.
The backend consists of four components.
The actual webservice:
As well as three pre-processing components:
The webservice offers data search as well as repository maintainance functionality via a REST API.
The API specification is here.
The Javadoc for the API-methods is here.
The most important methods are described in detail below:
The Constrained Table Expansion allows the user to extend a given table with an additional column. This is done by finding the data necessary for populating this additional column within a repository of data tables.
There are two methods that can be used for finding the right data for populating the additional column: Keyword-based Search and Correspondence-based Search.
The keyword-based search method allows the user to extend a given table with an additional column. This is done by finding the data necessary for populating this additional column within a repository of data tables.
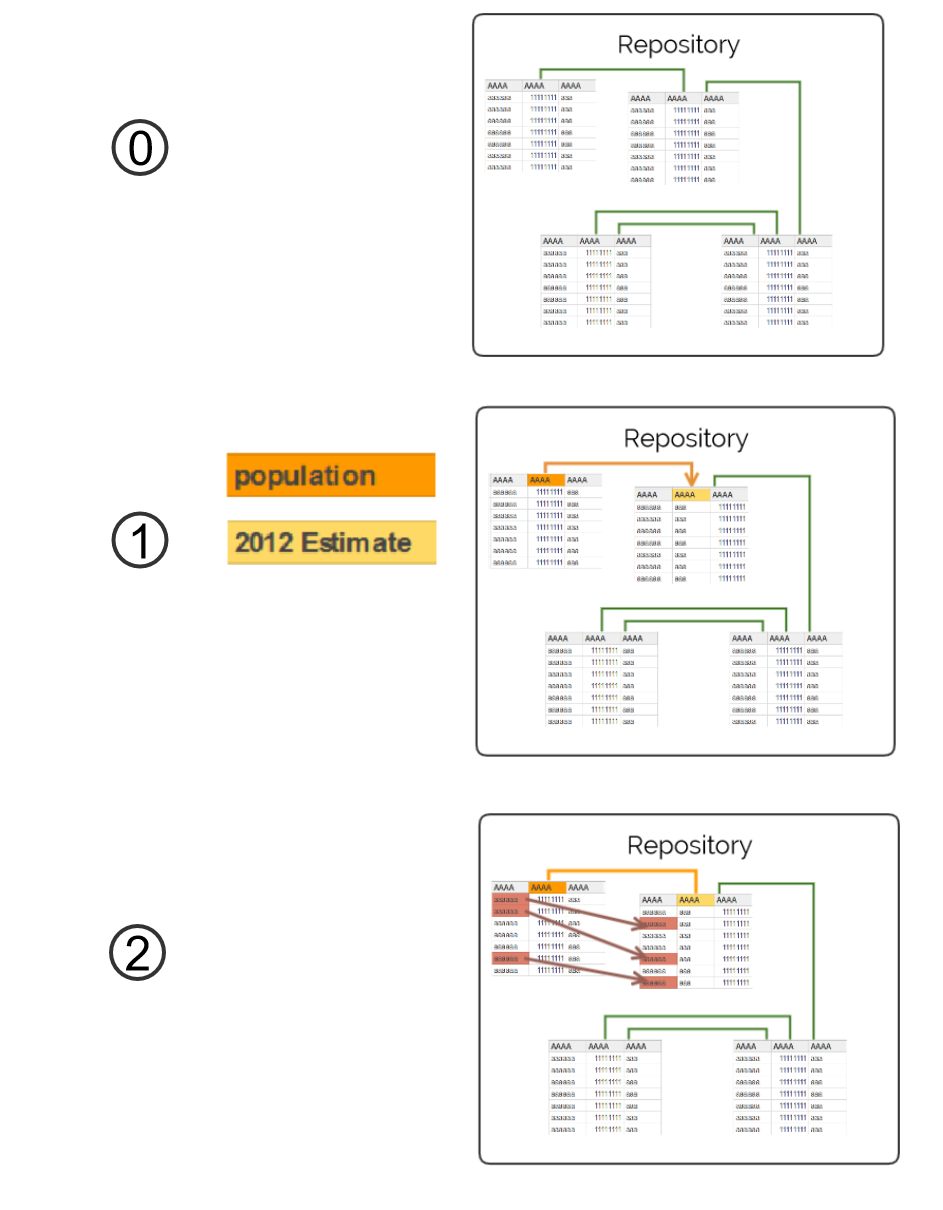
Lets assume that a user has loaded a table describing countries into RapidMiner. The table has the two columns "country" and "GDP". The user now wants to have the additional column "population" added to the table and filled with data from the corpus - see step ⓪ in figure below.
In step ①, the keyword-based search algorithm searches for tables in the repository, that have a column with a column name similar to "population". Afterwards (step ②), the algorithm determines correspondences between instances (rows) in the found tables and rows the query table, by comparing the subject-column values of these two tables – in our case: comparing the names of the countries. For the comparison, the subject column values are normalized and compared using Fuzzy-Jaccard with a threshold of 0.75. The threshold can be changed in the config-file. The identification of the subject columns is done by a combination of the same string comparison on column headers and a subject-column-detection algorithm [1].

The correspondence-based search method performs the same task as the keyword-based search: find tables that are relevant for table expansion within a repository of tabular data. The correspondence-based search however aims at achieving complete results by employing pre-calculated correspondences between the tables in the repository - see ⓪ in the figure below. These schema- and instance- correspondences between tables in the repository are calculated during the creation of a repository. The method that is used to discover the correspondences is described below.
The correspondence-based search addresses the following limitation of the keyword-based search:
If you want extend your table with the additional column “population”, the keyword-based search will not return tables containing an "inhabitants" column as the name of this column is too different from the name “population”. Nevertheless, the column "inhabitants" may contain data that is relevant for extending the query table.
The correspondence-based search method deals with this problem by using pre-calculated correspondences to expand the query result and return a more complete set of relevant tables: Initially, the method employs the same approach as the keyword-based method to find an initial set of tables that contain a column having a name similar to "population". Afterwards, the method searches the pre-calculated schema correspondences for correspondences that connect the discovered population columns with population columns in additional tables which have not been identified based on the column name yet. For instance, as the method for generating the correspondences also considers data values and not only column names, a pre-calculated correspondence could connect an “2012 Estimate” column in another table with a population column in one of the discovered tables and the table containing the “2012 Estimate” column would consequently also be added to the set of relevant tables ①. The pre-calculated correspondences also come to play for finding instance correspondences. In addition to comparing subject column values using string similarity - as in the keyword-based search – the pre-calculated instance correspondences are used to identify rows in the additional tables that describe entities which also appear in the query table ②. Again, as the instance correspondences are pre-calculated by not only comparing subject column values but also considering the values from other columns, the set of instance correspondences that is returned to RapidMiner is more complete than the set that results from only comparing subject column values.
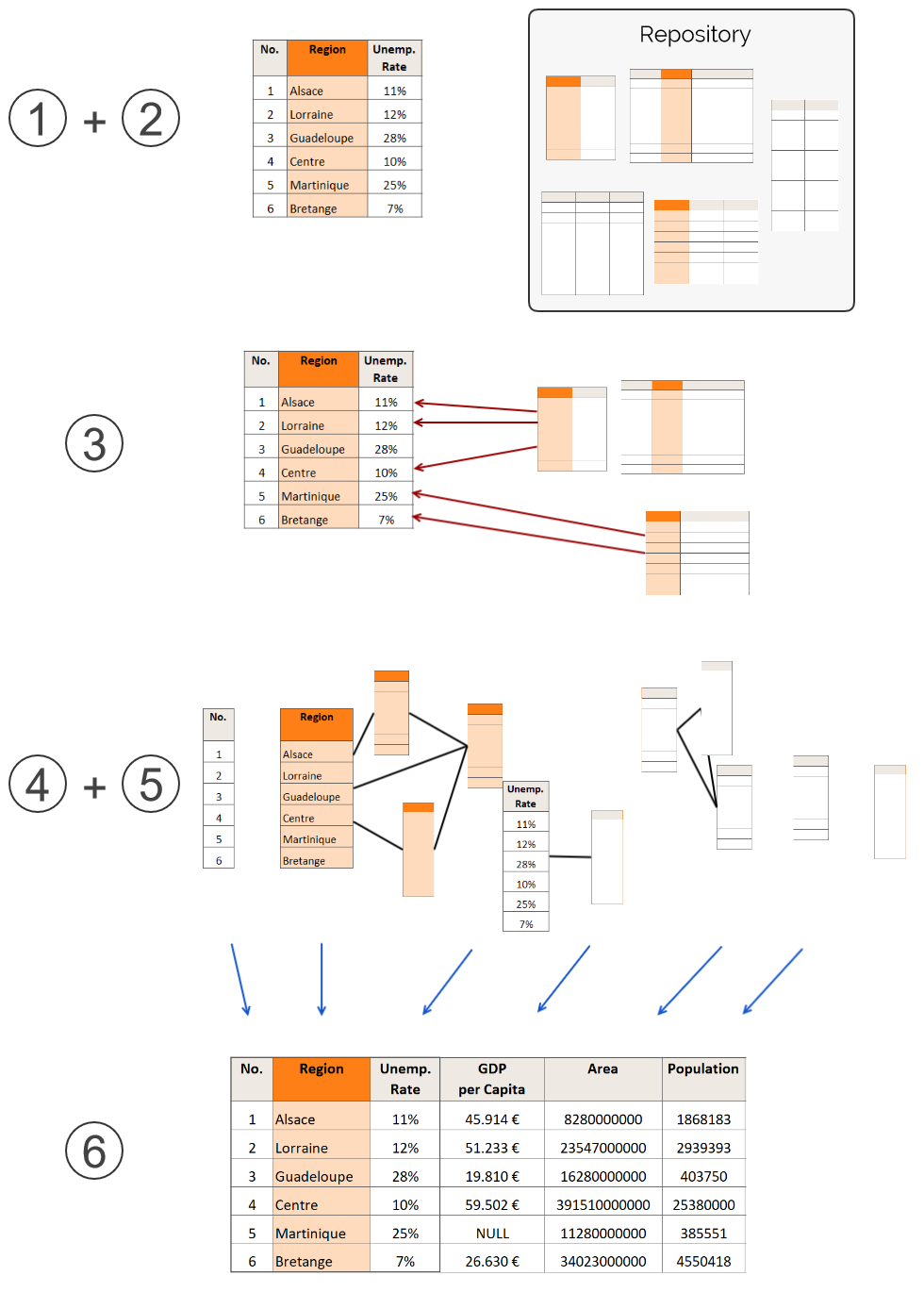
The Constrained Table Extension extends a provided table with exactly one additional column. The Unconstrained Table Extension on the other hand extends the provided table with as many columns as possible.
There is the restriction that the new extension columns have to have a minimum density of 10%. Another difference between the Constrained Table Extension and the Unconstrained Table Extension is the following: For the Constrained Table Extension the Backend API functions search for the correct data and the correspondences needed for fusing the data/populating the extension column, the actual fusion and population however happens in the front-end. This allows the user greater control over the fusion process. For the Unconstrained Table Extension on the other hand the fusion and population is done in the backend, as there are just too many variables involved for a user to effectively manage the fusion process.
The Algorithm for Unconstrained Table Extension works in the following way:
(An illustration of the steps is in the figure below.)
The Unconstrained Table Extension can add over 100 columns to a provided table (when the used repository is large). This amount of columns can be overwhelming for the user. The Correlation-based Table Extension was developed in order to address this issue. Instead of extending a provided table with as many columns as possible, it extends the provided table only with those columns that correlate to a specified attribute in the provided table – the ‘correlation attribute’.
In practice the Correlation-based Table Extension is implemented as an extension of the Unconstrained Table Extension. In the first step the Unconstrained Table Extension is used to add as many columns as possible to the provided table. In the second step ‘Correlation-based Filtering’ is applied to the extended table in order to only keep those columns that correlate with the correlation attribute.
The Unconstrained Table Extension Algorithm is described above. The Correlation-based Filtering Algorithm goes through the following steps:
Many use cases not only require extending local tables with data from public webtables, but users would like to extend tables using their own data, for example internal data from within a compary.
The UploadTable functionality allows users to create their own table repositories on the server and upload tables into these repositories.
The backend indexes the uploaded tables using the IndexCreator Component. The backend also uses the CorrespondenceCreator Component to discover instance- and schema-correspondences between uploaded tables and tables that are already contained in a repository. These correspondences are employed afterwards by the correspondence-based search.
The WebtableExtractor extracts tables from HTML pages and transforms them into the representation that is used by the other components of the backend.
The Extractor is currently implemented as a batch process. We assume that input data is stored locally, e.g. in the form of HTML pages.
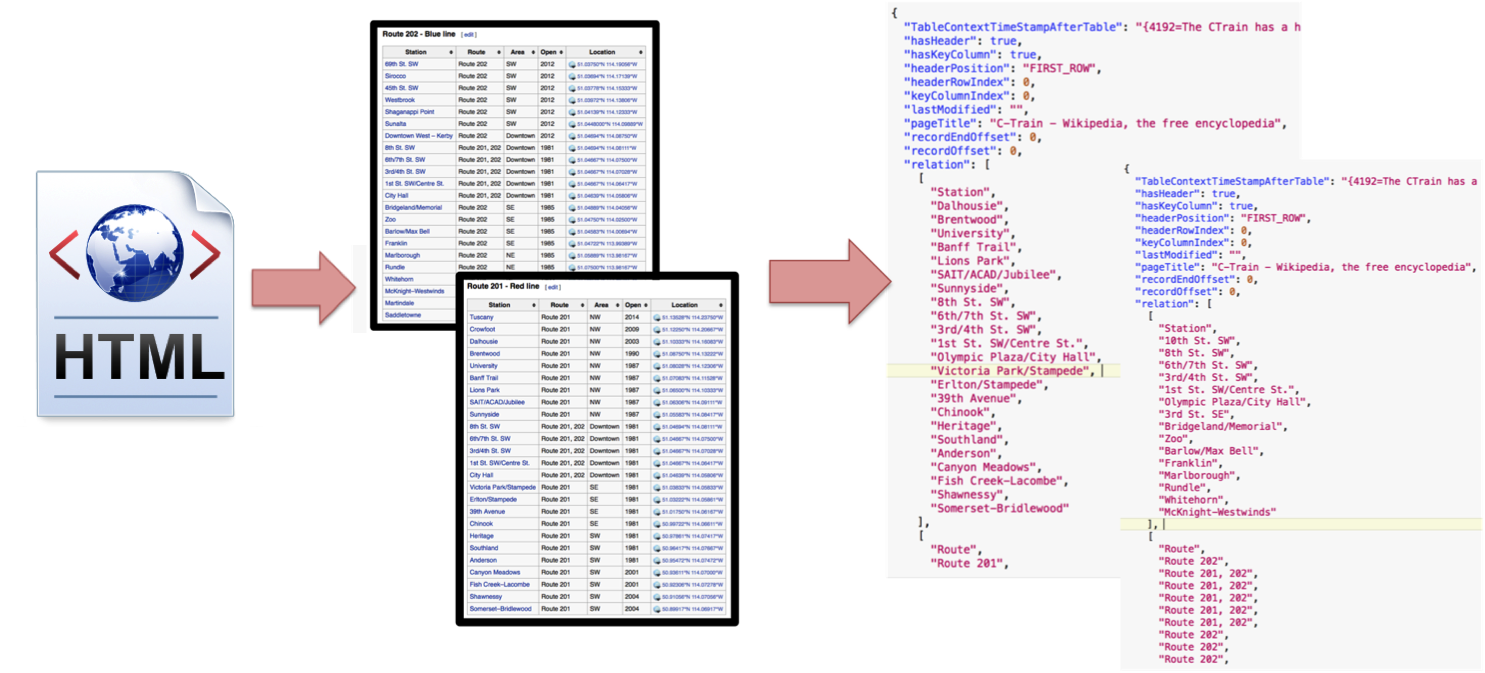
The process iterates over the locally stored pages, extracts useful tables and represent the output in a standardised format. The extraction is performed with BasicExtraction algorithm which iterates through tables in the HTML page using the "table" tag. Heuristics are used to discard noisy tables:
The remaining tables are classified as "layout" or "content" tables. The classification is done with the classifyTable method. It uses two models (SimpleCart_P1 and SimpleCart_P2). The first model identifies if the table is a LAYOUT table (only used for visualization formatting purposes). If this is not the case, then the second model is used to classify a table as:
For all retained tables, the method additionally identifies:
The key column detection selects the column with the maximal number of unique values. In case of a tie, the left-most column is used. The header detection identifies a row which has a different content pattern for the majority of its cells, with respect to the other rows. Currently this test is performed only on the first non-empty row of the table against the others. As context information for each table we select 200 characters before and 200 after the table itself.
The DS4DM webservice has to be fast at identifying the correct tables to return to the DS4DM RapidMiner operator. To achieve this speed despite the large corpus of data tables it has to search through, indexes are needed. In total 3 lucene indexes are used; they contain information about the data tables in the webservice's corpus.
The IndexCreator creates the following 3 Lucene indexes:
When a repository of data tables is created, the CorrespondenceCreator is automatically run. The CorrespondenceCreator finds correspondences between tables in the repository. These correspondences are later used by the Correspondence-based Search to improve its search results.
The following types of correspondences are generated:
In order to find these correspondences the CorrespondenceCreator executes the following steps:
Steps 2. and 3. of the correspondence creation process are implemented using the WInte.r Data Integration Framework.
In the following, we evaluate different aspects of the DS4DM backend components. First, the T2D Goldstandard is presented. This Goldstandard was used for many of the evaluations. Afterwards, the evaluations of the Constrained-, the Unconstrained- and the Correlation-based- Table Extension are presented. Finally, the Table Upload Functionality and the Preprocessing Components are evaluated.
The data from all the evaluations can be downloaded here.
T2D Goldstandard
For multiple of the evaluations, the T2D Goldstandard V2 is used. This is a collection of 779 tables that were extracted from HTML pages and cover a wide range of topics - such as populated places, organizations, people, music, etc. The tables were manually mapped to the DBpedia knowledge base. For our evaluation, we derive schema- and instance-correspondences between the different tables of the goldstandard by looking for pairs of schemas/instances that both have been mapped to the same DBpedia entry.
Evaluation of the Constrained Table Extension
The evaluation data can be downloaded from here.
We measure the density (completeness) of the attribute that is added to different query tables as well as the quality of the values of the newly added attribute. We use the T2D Goldstandard V2 for the evaluation.
For evaluating the table search methods we use fifteen different query tables that each should be extended by one specific attribute. Using the correspondences of the T2D Goldstandard, we inferred the best possible population of this extension attribute for the fifteen tables. The evaluation results below where calculated by comparing the values of the extension attributes that were added to the tables by the two search algorithms with the optimal values of the attributes as derived from the goldstandard. The complete details about the evaluation including the 15 query tables as well as the content of the attributes that were added to the tables can be found here.
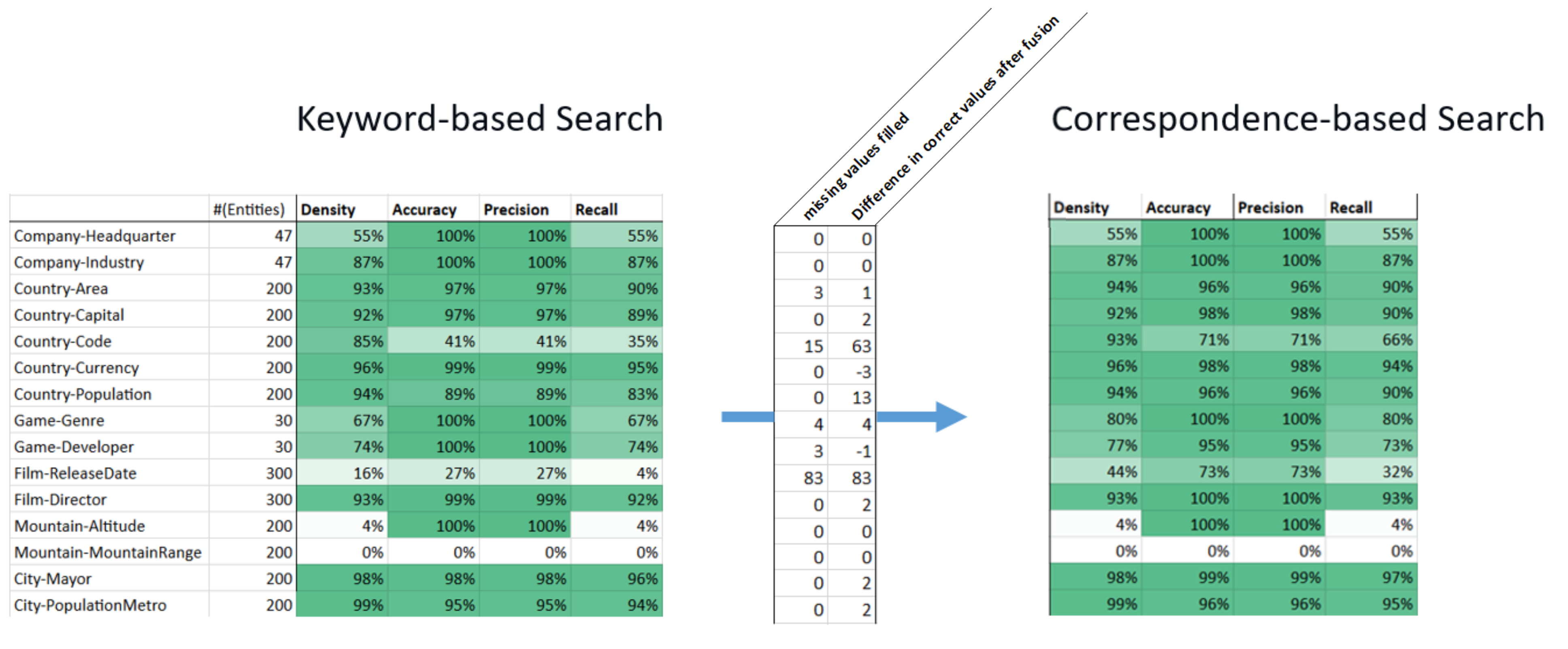
The table on the left contains the results obtained using the keyword-based search method. You will notice, that in general the algorithm was able to populate the extension column with a high density and accuracy. There are two exceptions for which the algorithm as not able to populate the extension column properly: Mountain-MountainRange and Film-ReleaseDate.
The table on the right shows the results of the correspondence-based search method. Especially for Film-ReleaseDate and Country-Code, due to the additionally found data, many more values in the extension column could be populated (“missing values filled” is high).
In the special cases of Country-Currency and Game-Developer, some of the additionally found data was wrong. In this case, extension-column values which had previously been correctly populated, now were wrongly populated (negative “difference in correct values after fusion” values).
Evaluation of the Unconstrained Table Extension
The evaluation data can be downloaded from here.
For the evaluation of the Unconstrained Table Extension, 13 different tables with different types of entities (Airports, Currencies, Lakes, etc.) were extended using the tables from the T2D Goldstandard as repository. The resulting extended tables were compared with ideal solutions to calculate the Precision-, Recall- and F1- scores shown below.
The ideal solutions were generated the following way:
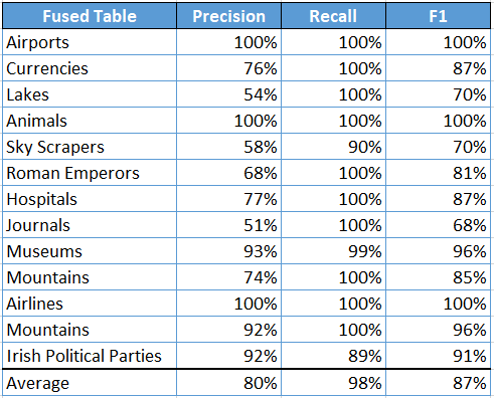
Analysis of the results
The Recall is better than the Precision for most of the examples. This is because the ideal solutions were generally not as well populated as the results of the Unconstrained Table Extension. The ideal solutions only contained values that have entity- and schema- correspondences to other tables, whereas the results used all values from the found tables.
A lot of the other differences can be explained by the quality and the similarity of the underlying tables – for Lakes and Journals the underlying tables were very different; for Animals and Airlines they were very similar.
Evaluation using Product Data from different E-Shops
Another evaluation of the Unconstrained Table Extension was performed using product data that had extracted from thirteen e-shops using a focused crawler. The Evaluation was performed in much the same way as with the T2D_Goldstandard data (see above).
The evaluation data as well as a detailed description of the evaluation setup is found here.
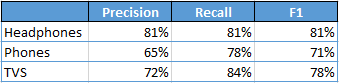
Evaluation of the Correlation-based Table Extension
The evaluation data can be downloaded from here.
The Evaluation of Unconstrained Table Extension was done with 13 query tables. For the evaluation of the Correlation-based Table Extension, from these thirteen tables, the four were considered that have the most numerical columns.
For these tables the additional columns found by the Correlation-based Table Extension were compared with the columns found when applying the Correlation-based Filtering to the ideal solutions.
The following results were obtained:

Analysis of the results
The scores are not 100%, because the Unconstrained Table Extension doesn’t work perfectly. The recall is better, because the tables generated by the Unconstrained Table Extension generally have more columns. So, more of columns are found to be correlating. Other things that cause wrong correlations are: columns with very low density, values with different measurement units (e.g. km2 and m2) in the same column.
Evaluation of the Table Upload Functionality
The uploadTable functionality allows users to add individual tables to an existing corpus of tables.
The uploaded tables are indexes and correspondences are created between the newly uploaded table and the tables that are already in the repository. Uploading and indexing 1000 tables one by one takes approximately 2 hours (7.2 seconds per table).
Alternatively, the bulkTableUpload functionality can be used for uploading larger amounts of tables. Processing the same 1000 tables using the bulkTableUpload only requires 10 minutes (0.6 seconds per table).
These times were measured using a machine with 13GB of RAM and four 2.6GHz processors.
Evaluation of the Preprocessing Components
The evaluation data can be downloaded from here.
We also use the T2D Goldstandard for evaluating the quality of the instance- and schema-level correspondences between tables that are discovered by the CorrespondenceCreator.
The matching method that is employed by the CorrespondenceCreator reaches the following F1 scores:
The Perfomance of the Backend components was evaluated using the Wikitables dataset.
This dataset consists of 1.6 million tables out of which 541 thousand are relational tables with a subject column and a minimum size of 3x3.
The IndexCreatior needs 2 hours to index these 541 thousand tables.
The CorrespondenceCreator needs 4 days to process theses tables.
These times were measured using a machine with 8GB of RAM and a 3.1GHz processor.
The evaluation data can be downloaded from here.
The CorrespondenceCreator employs a blocking step to reduce the number of table comparisons that are needed for identifying correspondences.
The blocking technique clusters tables using a bag-of-words approach. When used to find likely matching pairs in the T2D Goldstandard, the blocking technique achieves a reduction ratio of 0.992 and a pair completenes of 0.701.
The harmonic mean of these two values is 0.822.


